모두가 알고 있는 사실이지만, GPT는 거짓말을 잘합니다.
GPT가 처음 나왔을 때부터 사용해왔고, 아마 누구보다 많이 욕했을 겁니다.
말은 알아듣지도 못하고, 거짓말은 일상에 가격까지 비싸니까요.
답답해서 "LLM의 원리를 알면 더 효율적으로 사용할 수 있지 않을까?"로 시작한 게 여기까지 올 지는 몰랐지만, 아무튼 할루시네이션을 줄이고, 실제 고객에게 상용화가 가능한 수준의 프롬프트를 만들기까지 거쳐온 시행착오와 과정을 풀어보려 합니다.
그 첫 단계로, 이번 글에서는 LLM이 어떻게 작동하는지를 풀어봅니다.
저는 개발자도 아니고 머신러닝은 처음 접한 비개발자이자 기획자입니다. 이 글은 저처럼 AI를 도구로 다루고 싶은 기획자를 위해 썼습니다.
전문가는 아니지만, 기획자의 언어로 이해가 가능하도록 설명해보겠습니다.
한눈에 훑는 흐름
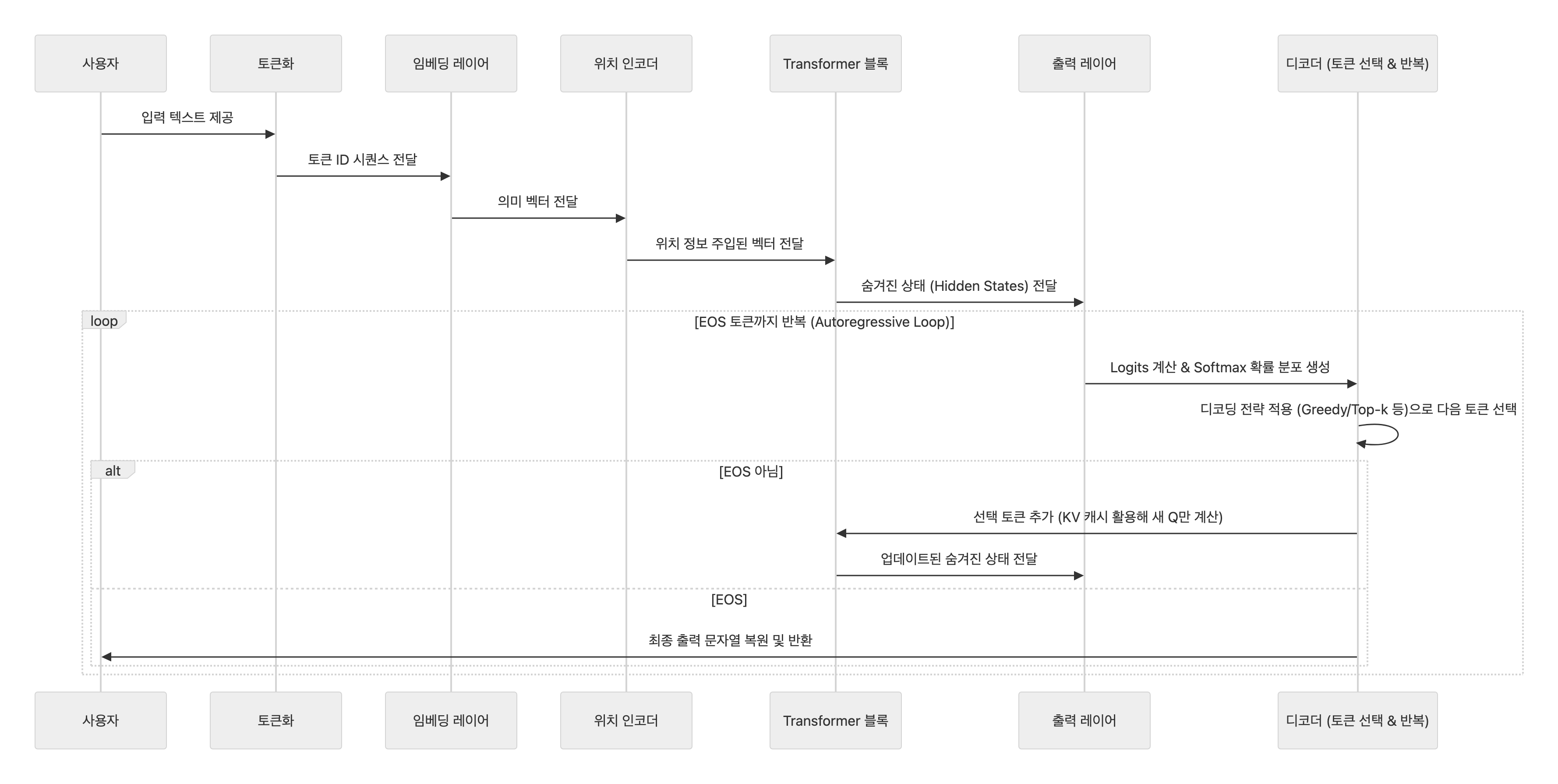
1) 텍스트를 모델이 읽을 크기로 쪼갠다 — 토큰화(Tokenization)
설명
입력된 프롬프트, 즉 텍스트를 모델이 처리할 수 있는 최소 단위로 쪼개는 과정입니다. 이를 토큰화라고 부르며, LLM의 첫 번째 단계입니다.
왜 필요하나
LLM은 문자를 직접 이해하지 못합니다. 텍스트를 숫자로 변환해야 연산이 가능하며, 토큰은 그 최소 단위입니다. 특히 한국어처럼 조사와 어미가 복잡한 언어에서는 서브워드(단어 조각) 단위로 쪼개어 효율적으로 처리합니다.
어떻게 동작하나
예: “나는 밥을 먹었다” → BPE(Byte Pair Encoding)는 자주 등장하는 글자 조합을 기반으로 서브워드(subword)를 만듭니다. 따라서 이 문장은 모델에 따라 [나, 는, 밥, 을, 먹, 었, 다] 혹은 [나는, 밥을, 먹었다]처럼 쪼개집니다. 각 토큰에는 고유 숫자 ID를 매핑해 숫자 시퀀스로 변환됩니다.
비유
문장을 레고 블록으로 분해하고, 각 블록에 번호(ID)를 붙이는 과정. 블록이 작을수록 유연하게 재조립할 수 있습니다.
이해하면 좋을 포인트
- 토큰 수가 비용과 속도를 결정합니다. 동일 의미라도 장황한 표현은 토큰을 증가시켜 비용이 올라갑니다.
- 기획 팁: 프롬프트를 영어로 작성하면 토큰 수가 1.5~2배 줄어 비용 절감. 한국어 서비스라면 토큰 효율적인 토크나이저(GPT-4o 등)를 선택하세요. (토큰 수 계산 : https://platform.openai.com/tokenizer)
2) 의미를 숫자 공간에 심는다 — 임베딩(Embedding)
설명
토큰 ID를 고차원 벡터(의미 좌표)로 변환하는 단계로, 단어의 의미를 숫자들의 배열로 표현합니다.
왜 필요하나
ID만으로는 의미가 없기 때문입니다. 벡터로 변환하면 비슷한 단어(예: '밥'과 '식사')를 공간상 가까이 배치해 비교·연산이 가능해집니다.
어떻게 동작하나
사전 학습된 임베딩 모델의 벡터 공간에서 ID에 해당하는 벡터를 가져옵니다. 이 테이블은 모델 훈련 중 업데이트되어 의미를 학습합니다. 하지만 이 단계까진 문장 순서를 고려하지 않습니다.
비유
세계 지도에 단어를 배치하는 것: '사과(과일)'와 '바나나'는 가까운 좌표, '사과(회사)'는 멀리 떨어집니다.
이해하면 좋을 포인트
- 차원이 클수록 뉘앙스 구분이 정교하지만, 메모리와 연산이 증가합니다.
- 기획 팁: 도메인 specific 서비스(예: 법률 AI)라면 fine-tuning으로 임베딩을 맞춤화해 정확도를 높이세요.
3) “몇 번째인지”를 알려준다 — 위치 정보(Positional Encoding / RoPE)
설명
임베딩 벡터에 토큰의 순서 정보를 추가하는 과정입니다.
왜 필요하나
순서가 바뀌면 의미가 달라집니다(예: "The dog bit the man" vs "The man bit the dog"). 의미 벡터만으로는 이를 구분할 수 없습니다.
어떻게 동작하나
- 고전 방식: 의미 벡터에 사인/코사인 기반 위치 벡터를 더합니다.
- 최신 추세: RoPE(Rotary Position Embedding) – 쿼리/키 벡터를 위치에 따라 회전시켜 상대적 거리를 자연스럽게 반영. 긴 문맥(128k 토큰 이상)에서 안정적입니다.
비유
오케스트라 자리배치: 같은 악기라도 앞/뒤 좌석에 따라 전체 소리에 미묘한 차이가 생깁니다.
이해하면 좋을 포인트
- 이로 인해 최종 입력 벡터(의미 + 위치)가 모든 계산의 기반이 됩니다. 순서를 '추측'하는 게 아니라 처음부터 포함됩니다.
- 기획 팁: 긴 대화 챗봇 서비스라면 RoPE 기반 모델(Llama 시리즈)을 우선 고려해 컨텍스트 길이를 확장하세요.
4) 단어들이 서로를 참고한다 — Transformer & Self-Attention
설명
전체 문맥을 고려해 토큰 간 관계를 계산하는 핵심 메커니즘입니다.
왜 필요하나
단어 하나만으로는 다의어(예: 'bank' – 은행/강둑)나 관계를 판단하기 어렵습니다. Self-Attention으로 문맥을 보며 '누구를 얼마나 참고할지' 결정합니다.
어떻게 동작하나
- 입력 벡터에서 Q(질문), K(키: 특징), V(값: 정보)를 생성.
- 모든 토큰의 Q와 K를 내적해 유사도 계산, softmax로 참고 비율 만듦.
- 비율대로 V를 가중 평균해 새 표현 생성(문맥화).
- 여러 헤드가 병렬로 서로 다른 관점을 봅니다.위치적 관계(문장 내 단어 위치), 의미적 관계(유사한 의미 파악), 문맥적 관계나 분위기 등을 동시에 포착합니다.이후 결과를 합치고, Residual 연결·LayerNorm·FFN(Feed-Forward Network)을 포함한 블록을 여러 층 반복하며 추상화가 깊어집니다.
비유
토론: 각 학생(Q)이 다른 학생(K)의 말을 듣고, 필요한 정보(V)를 취합해 의견을 형성합니다.
이해하면 좋을 포인트
- 계산 복잡도 O(n²): 토큰 길이 n이 2배면 연산 4배. 긴 프롬프트는 비용 급증.
- 기획 팁: Attention 비용 때문에 컨텍스트 윈도우를 제한하거나 RAG로 필요한 정보만 주입하세요. A/B 테스트로 최적 길이 찾기.
5) 다음 토큰을 예측하고 문장을 이어 붙인다 — 예측, 디코딩 & 반복(Autoregressive Loop)
설명
모델이 다음 토큰을 확률적으로 선택하고, 이를 반복해 응답을 생성하는 과정입니다.
왜 필요하나
LLM은 한 번에 전체 문장을 생성하지 않습니다. 다음 토큰 하나씩 예측하며 이어가야 자연스러운 출력이 나옵니다. EOS(End of Sequence) 토큰으로 종료합니다.
어떻게 동작하나
- 예측: 최종 표현 × 출력 행렬 → logits(점수) → softmax로 어휘(V) 전체 확률 분포 생성.
- 디코딩 전략: Greedy(최고 확률 선택: 안정적), Top-k/Top-p(상위 후보 샘플링: 다양성), Temperature(분포 조절: 낮으면 사실적, 높으면 창의적).
- 반복: 선택 토큰을 입력에 추가, KV 캐시(과거 Key/Value 재사용)로 효율화. 새 Q만 계산해 속도 ↑, 메모리 ↑.
비유
객관식 시험처럼 모든 보기(V)에 점수를 매기고, 가장 자연스러운 답을 골라 문장을 한 줄씩 이어 쓰는 작가 과정.
이해하면 좋을 포인트
- 출력 길이도 비용: 매 스텝마다 V 크기 계산 반복.
- 기획 팁: 프롬프트에 "3포인트로 요약, 200자 이내" 지정으로 EOS 유도와 비용 관리. Temperature 0.7로 창의적 응답, 0.1로 사실적 응답 유도.
번외) 왜 이렇게 비싸고, 어떻게 빠르게 만드나 — 복잡도 & 최적화
- 비용 포인트
- Attention: O(n²) – 길이에 제곱 비례.
- Softmax: O(V) – 어휘 크기만큼, 매 스텝 반복.
- 최적화 예시
- KV 캐시: 추론 가속, 하지만 긴 시퀀스에서 메모리 증가.
- 제품 설계: RAG(검색으로 핵심 컨텍스트만 추가), 프롬프트 압축, 형식 제약으로 n 줄이고 반복 제한.
기획 팁: 최적화 지원 모델(예: GPT-4o with FlashAttention) 선택. 비용 모델링으로 서비스 가격 책정.
기획자를 위한 체크리스트
| 항목 | 설명 | 방법 |
| 컨텍스트 최적화 | n² 부담 줄이기 | 프롬프트 요약/불릿/표 활용, RAG로 핵심 정보 주입 |
| 형식 지정 | EOS 유도와 출력 제약 | "3포인트로, 200자 이내" 프롬프트 추가로 품질/비용 관리 |
| 사실성 강화 | 환각 방지 | 파라미터만 믿지 말고 RAG/API 연동으로 외부 근거 투입 (정확도 ↑) |
| 비용 모델링 | 토큰/길이 기반 비용 예측 | A/B 테스트로 최적 프롬프트 찾기, 영어 우선 고려 |